Preamble to Data Management Plan
Last updated on 2025-01-07 | Edit this page
Overview
Questions
- What is Metadata?
- How to describe metadata?
- What is the difference between data and metadata?
Objectives
- Defining data management plan.
- Understanding its importance applied to OMICs experiments.
Introduction
In this lesson, we will learn about metadata and its importance. We will learn about the different types of metadata and how it is used to provide context and meaning to data. We will also learn about the importance of metadata standardization and how it can help to improve data management and data analysis. Finally, we will learn about the importance of metadata in OMICs experiments and how it can help to improve the reproducibility and reliability of research results.
What is Metadata?
Metadata is data that provides information about other data. It is an essential component of any data analysis pipeline. It is used to describe the content, quality, condition, and other characteristics of data. Metadata is used to provide context and meaning to data. It is used to help users understand the data and to help them make informed decisions about how to use it.
Data vs. Metadata
Data is the raw information that is collected and analyzed in a research study. It is the information that is used to answer research questions and to make decisions. Metadata is the information that describes the data. It is the information that provides context and meaning to the data. It is used to help users understand the data and to help them make informed decisions about how to use it.
An everyday analogy is digital photography. Every time you take a photo with a digital camera, a range of “behind-the-scenes” information is saved along with the image data. This is known as metadata, and it can include details of the camera, lens, and shooting settings used, plus optional information about the photographer, location and more. Similarly, every experiment generates data, and contains metadata.
An experimental protocol, for example, is considered part of the metadata of an experiment. There are different levels of metadata, which will be discussed in more detail once we discuss the ISA (Investigation, Study and Assay) framework.
Data management plan
A data management plan (DMP) is a document that outlines how data will be handled throughout a research project. It explains how to collect, organize, store, and share data, as well as ways to make sure that data is safe and meets legal and ethical standards. The DMP aims to enhance the accessibility, usability, and reproducibility of the data, as detailed below.
Goals of data management plan
Here we define the goals of a data management plan in context to the FAIR framework:
- Automated deposition of data and metadata to public repositories (findability).
- Ensure that data is stored in a format that is easily accessible and usable (accessibility).
- Define consistent terminologies and controlled vocabularies to represent the data (interoperability).
- Ensure that data is stored in a secure and reliable manner (reusability).
Roles and responsibilities
- Data owners: Persons responsible for generating the data and metadata.
- Data managers: The person responsible for managing the data and metadata.
- Data users: The person responsible for using the data and metadata to answer research questions and make decisions.
Benefits of Data Management and Metadata Standardization
- Increase impact and visibility of research.
- Assigns clear responsibilities for data management tasks such as storage, backup, and controlled sharing.
- Standardizes data and metadata to facilitate collaboration using consistent terminologies and controlled vocabularies.
- Promotes collaboration within the CRC and with external partners, supporting method development and data reuse.
- Ensures compliance with funder requirements.
- Facilitates efficient interoperability among infrastructure teams.
- Enable audit trail of data and metadata changes.
Metadata management plan and FAIR framewok
In this document we outline the strategies and procedures for managing high-throughput data within the CRC1550’s integrated infrastructure. The CRC-INF plan is centered on the consolidation of interfaces, procedures, and interoperability standards (Aim 1) and the development of generic bioinformatics workflows for the standard analysis of multimodal data sets from CRC projects (Aim 2). The primary objective of the data management team is to ensure the efficient management of unprocessed and processed data produced by high-throughput experiments by providing services (and interfaces) to manage and store data and metadata.
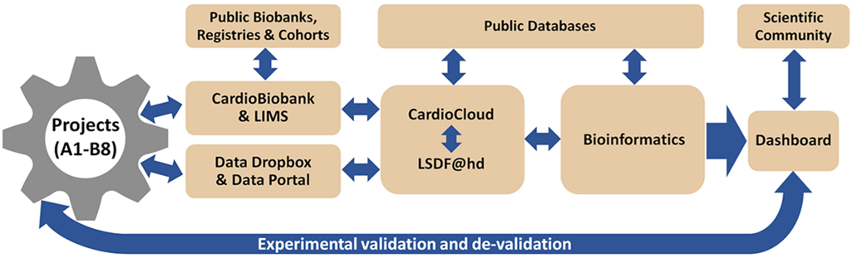
There are three working groups:
The BioBanking working group is responsible for the collection, storage, and management of biological samples.
The Data Management working group.
The bioinformatics working group is responsible for the analysis of high-throughput data.
This course is focused on the Data Management working group.
Findability
Metadata and data should be easily discoverable by both humans and machines. To ensure findability, each data object must have a unique and persistent identifier: - Data objects must be re-findable at any time, with an emphasis on maintaining persistent metadata. - Each data object should include basic machine-readable metadata to differentiate it from other objects. - Identifiers for concepts used in data objects must be unique and persistent.
Accessibility
After finding data, it’s crucial to understand the conditions for accessing them. Data should be accessible to both machines and humans:
- With proper authorization.
- Via a well-defined protocol.
This ensures that both machines and humans can determine the actual accessibility of each data object.
Interoperability
Data needs to be processed and, often, be integrated with other data sets and be compatible with various applications or workflows for analysis, storage, and processing.
Data objects are interoperable if: - The (meta)data is machine-actionable. - The (meta)data formats use shared vocabularies or ontologies. - The (meta)data within the data object is both syntactically parsable and semantically machine-accessible.
Reusability
The ultimate goal is to optimize the reuse of data, requiring that metadata and data be well-described for use, replication, and combination in various settings.
For data objects to be reusable, they must:
- Comply with principles of findability, accessibility, and interoperability.
- Be sufficiently well-described and rich in metadata to allow automatic linking or integration with relevant data sources, with minimal human effort.
- Include rich metadata and provenance information for proper citation of published data objects and their sources.
Conclusions
Data and metadata standardization and description involves establishing and applying rules and guidelines for creating, managing, and using metadata. This process ensures that metadata is reliable and helps users more effectively find, access, and utilize data.
Key Points
- Data management plan execution enables data FAIRification.
- Metadata standardization is critical for reliable results and reproducibility.
- There are three roles in data management: data owners, managers, and users.
- Data management and metadata standardization provide numerous benefits that enhance the overall quality, usability, and impact of research data.